|
Path-LZerD: Multimeric Protein Complex Assembly Order Prediction
Updates
- 2018-06-06 added case1-3 data files.
Introduction
Path-LZerD predicts the assembly order of a protein complex by simulating its assembly process. Many important functions in a cell are carried out by protein complexes with more than two subunits. Similar to folding of a single protein, multimeric protein complexes in general follow an energetically-favored assembly path. Path-LZerD predicts the assembly path of a complex by simulating docking process of the complex. Path-LZerD takes subunit structures as input, assembles them into protein complex models using a multimeric protein docking protocol, and predicts assemble pathway of the complex from actually observed pathways in the docking process.
Overview of Path-LZerD
Path-LZerD uses a multiple-protein docking algorithm (Multi-LZerD) which assembles a protein complex structure from individual subunit structures. By analyzing the assembly pathways of predicted complex models, Path-LZerD predicts the assembly order of the protein complex.
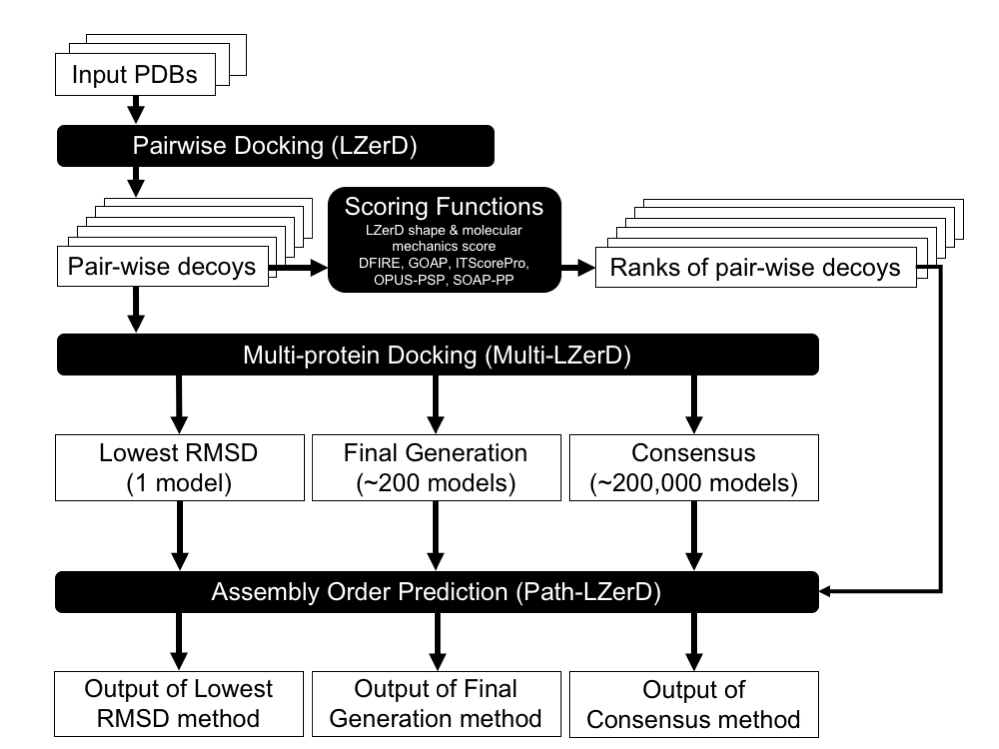
In the first step, all pairwise combinations of input subunit structures are docked by a pairwise protein docking method, LZerD.
In the second step, models of the entire complex are built by Multi-LZerD by combining the pair-wise docking predictions generated in the first step.
In the third step, the pairwise decoys for each subunit pair were ranked by a scoring function which evaluates the binding energy of decoys.
In the final step, the assembly order of the target complex is predicted by comparing the score ranks of the pairwise decoys that were assembled by Multi-LZerD to obtain the whole complex model.
Download Path-LZerD
The current version of Path-LZerD as used in the paper is available as a zip file.
Download Path-LZerD Programs.
Download MultiLZerD for Path-LZerD.
Download Case1 Data (1a0r)
Download Case2 Data (1gpq)
Download Case3 Data (1w88)
Tutorial
Getting Started
Download and save the zip file of the program in your preferred directory.
The files can be unpacked using the commands:
unzip path_lzerd-master.zip
The generated Directory contains the files:
- LICENSE.txt
- lzerd_pdbgen.py
- path_lzerd.py
- PATHS.ini
- README.md
- score_pair.py
- SCORES.py
- shared.py
- test
|
Path-LZerD requires a pairwise protein docking program LZerD and a multiple protein docking program Multi-LZerD.
They are available in the LZerD docking suite at the Kihara Lab website: LZerd page
and Multi-LZerD page.
Path-LZerD also requires the following external programs and python modules:
- DFIRE
- GOAP
- ITScorePro
- SOAP-PP
- OPUS-PSP
- ProFit
- Python modules: numpy, pandas, modeller, mdt
- To install the required python modules, users can use the following commands with Anaconda:
conda config --add channels salilabconda install modellerconda install -c salilab mdt
|
|
Once all external programs and python modules are installed, PATH.ini should be modified according to the environment of user’s computer. This file specifies the location of the programs.
Example of PATH.ini:
[required]
lzerd_path: /home/user1/lzerddistribution/
multilzerd_path: /home/user1/multilzerd/
[optional]
goap_path: /home/user1/bin/goap-alone_long
itscorepro_cmd: /home/user1/bin/ITScorePro
soappp_cmd: /home/user1/bin/soap_pp/soap_pp.py
modeller_cmd: python
opuspsp_path: /home/user1/bin/OPUS_PSP/
|
Running the Program
Path-LZerD to make assembly path prediction using the output files (.ga.out) of Multi-LZerD.
Before running the Path-LZerD script, users have to put the following files to the same directory.
Here, we explain how to run Path-LZerD on the sample data, which are provided in the test directory.
- Input PDB files: Path-LZerD requires the same input PDB files that are used in the Multi-LZerD step (B-1A0R.pdb, G-1A0R.pdb and P-1A0R.pdb).
- The output files of pairwise docking by LZerD runs (B-G.out, B-P.out and G-P.out).
- The output file that contains multiple docking decoys by Multi-LZerD (finalgene.ga.out).
In the test directory, run_test.sh was described as
#!/bin/bash
PATH_LZERD_HOME=".."
path_lzerd="$PATH_LZERD_HOME/path_lzerd.py"
cmd="$path_lzerd -p 1A0R -d . -g finalgene.ga.out -o finalgene_chain.csv”
echo $cmd
$cmd
After preparing all files, the Path-LZerD protocol will be executed by
% bash ./run_test.sh
in the test directory.
Result
The predicted assembly order is recorded in finalgene_chain.csv:
score,pathway,pdbid
dfirerank,BG>BGP,1a0r
soappprank,BG>BGP,1a0r
sumrank,BG>BGP,1a0r
goaprank,BG>BGP,1a0r
molmechrank,BG>BGP,1a0r
shapescorerank,BG>BGP,1a0r
opuspsprank,BG>BGP,1a0r
itscorerank,BG>BGP,1a0r
References
|
